Wouldn’t it be nice to know what fields are “unreferenced” in your document? By unreferenced, I mean fields that are not used in Expressions, Dimensions or Keys. These are fields that if removed from your document, would have no impact on the visible elements of the application.
Removing unused fields is sometimes important in addressing performance issues and generally makes your application easier to maintain and understand.
The Expression Overview dialog is great for finding where a field is used, but what about the unused fields? I don’t know of any QV supplied tool that can identify unused fields, so I created one myself. My tool is a QVW named “DocumentAnalyzer” and it’s available for download from:
http://robwunderlich.com/Download.html
First off, let me make it clear that this tool is imperfect. It’s difficult to do a precise field usage analysis from “outside” of the product. I hope that this work of mine will encourage (goad?) Qliktech into writing a field usage analysis tool within the QV product. I’ll be happy if my work becomes obsolete.
I’ll explain the usage and limitations of DocumentAnalyzer as well identify some interesting code tidbits for anyone who may want to enhance or borrow from this app.
The app code itself consists of two pieces. 1) A Macro Module that extracts meta information from the document to be analyzed (the “target” document) 2) A load script that processes the extracted meta data.
The Macro does a lot of filesystem access and requires System Access module security. If you have not allowed System Access, the macro will warn you and provide instructions for setting it.
Using DocumentAnalyzer is a two step process, driven by buttons in the Main sheet. The first step is to choose a target document. Pressing the button will bring up a standard windows file chooser dialog. If a file chooser dialog cannot be created, the user is instructed to type a filename directly in the input box.
Once a target document is selected, press the “Process Document” button. The Macro module will be invoked and extract the metatdata to a series of files in your temp directory. After extraction the load script will read the extracted files. At the end of the load script, the metadata files will be deleted.
The tool will open the target document and navigate through the screens. Keep your hands off the keyboard while this process runs. When the load script is complete, you’ll receive a msgbox like this. Press OK.
The first chart of interest can be found on the “Fields” sheet. The Field References chart lists each FieldName and indicates whether the FieldName was used as a Key, Dimension, In an Expression, Macro or Variable. FieldNames not referenced anywhere are highlighted in yellow. These are fields you might consider dropping from the document.
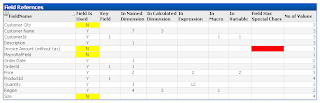
FieldNames that contain special characters are flagged in red. The usage of these fields cannot be accurately determined due to limitations of the parsing method I’m using.
The Exception sheet displays you may consider warnings about the data presented. Of particular interest is the “Unmatched Fields” listbox. Check out the Help in this listbox to understand it’s contents.
The Parsing Algorithm
The identification of field rerefences is performed by the load script. The parsing is rather primitive so I’ll provide some explanation here so you can understand it’s limitations. You can also find this information on the “About” sheet of DocumentAnalyzer.
Field names are discovered in expressions by replacing “special” characters with a delimiter and then parsing into words using the subfield() function. For example, the expression:
“Avg(Price * Quantity) * 1.05”is delimited to:
“AvgPrice Quantity 1.05”which is then parsed into four words — Avg, Price, Qty, 1.05 . The words are then matched against fieldnames. You will get a false match if a function name such as “Avg” is also used as a field name. If you just want use DocumentAnalyzer, no need to read further. If you want to learn something about the code, read on.
The Code
The Macro writes the metadata to a series of files. The files are normally deleted at the end of the script.
If you want to keep the metadata files, comment out this line in the script (on the Cleanup tab):
LET x = DeleteFolder(‘$(f)’); // Delete the data files
The Macro Module is of a fair size — about 500 lines. If you examine the code, you’ll find some conditional code (IsInternal()) devoted to allowing the macro to run internally in a qvw or externally from cscript.exe. The entire macro module can be copied to an external file and run with cscript. I coded for “dual” execution environments because I get a better editor and debugger in the external environment. I do the development running externally and then paste the script into the QVW for final testing.
Meta information (Field names, Dimensions, Expressions, etc) are extracted from the target document using the QV API. Getting Dimension values was fairly easy, they are only a few API paths for the various object types.
Finding all the expressions was the most challenging part and took the most time to solve. There are many different properties where expressions may be used in sheet objects. They may also differ by release. I could not see discovering and writing all the API calls to extract every possible expression. I experimented with a number of approaches, including generating code from the API doc — never got this to work correctly. The most promising approach was using the file export from the Expression Overview dialog. This gave me a complete list of expressions, but the exported file was not consistently usable. The export file is a tab delimited file. If an expression uses tabs or newlines it can make file impossible to navigate.
My eventual solution was to export the objects into XML using the
WriteXmlPropertiesFile outputFile API method and then extract the expressions from the XML files. I first tried to get the expressions using load script, but found this too cumbersome. I settled on using XPath to extract the data I needed from the XML files. XPath is a sort of “query language” for XML. Where SQL returns a set of rows, XPath returns a set of XML elements. This required only a few XPath expressions to cover all the possible expressions.
Once I perfected the XPath method, I switched to doing the Dimension extraction this way as well.
In QV 8.5, Sheets do not have an XML representation. So Sheet expressions (background color, conditional show, etc) are extracted indivdually.
The Document Variables. Macro Module and Script are written to files as well. The Script is not currently processed by the load.
Contact me if you have any problems or questions on using the app. Contact information is on the “About” sheet.
Happy analyzing!
-Rob













{kind=link}
{kind=link}