In Qlikview we have the ability to add function to the scripting language by writing VbScript in the document module (sometime called the “macro module”). Typical additions included regular expression matching & parsing,
Qlik Sense does not have the module feature, but both Sense and QlikView share a similar feature, Server Side Extension (SSE). SSE is typically positioned as a method to leverage an external calculation engine such as R or Python from within Qlik script or charts. The Qlik OSS team has produced a number of SSE examples in various languages.
SSE seems to be a good fit for building the “extra” functions (such as regex) that I am missing in Sense. The same SSE can serve both Sense and QlikView.
Installing and managing a SSE takes some effort so I’m clear I don’t want to create a new SSE for every new small function addition. What I want is a general purpose SSE where I can easily add new function, similar to the way QlikView Components does for scripting.
Miralem Drek has created a package, qlik-sse, that makes for easy work of implementing an SSE using nodejs. What I’ve done is use qlik-sse to create qcb-qlik-sse, a general purpose SSE that allows functions to be written in javascript and added in a “plugin” fashion.
My motivating principles for qcb-qlik-sse:
- Customers set up the infrastructure — Qlik config & SSE task — once.
- Allow function authors to focus on creating function and not SSE details.
- Leverage community through a shared function repository.
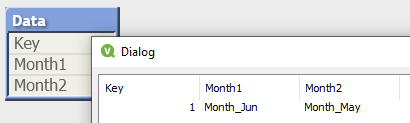
I’ve implemented a number of functions already. You can see the current list here. Most of the functions thus far are string functions like RegexTest and HtmlExtract that I frequently have implemented in QlikView module or I’ve missed from other languages.
One of the more interesting functions I’ve implemented is CreateMeasure(), which allows you to create Master Measures from load script. This is a problem I’ve been thinking about for some time and qcb-qlik-sse seemed to be a natural place to implement.
If you want to give qcb-qlik-sse a try, download or clone the project. Nodejs 8+ is required. Some people report problems trying to install grpc using node 12, so if you are new to all this I recommend you install nodejs v10 instead of the latest v12.
If you are familiar with github and npm, you will hopefully find enough information in the readme(s) to get going. If not, here’s a quickstart.
- Install nodejs if not already present. To check the version of nodejs on your machine, type at a command prompt:
node --version
- Download and extract qcb-qlik-sse on the same machine as your Qlik desktop or server.
- From a command prompt in the qcb-qlik-sse-master directory install the dependent packages:
npm install
- Configure the SSE plugin in Qlik. Recommend prefix is QCB. If configuring in QlikView or Qlik Sense Desktop the ini statement will be:
SSEPlugin=QCB,localhost:50051
- Start the SSE:
./runserver.cmd
The “apps” folder in the distribution contains a sample qvf/qvw that exercises the functions.
I’d love to get your feedback and suggestions on usage or installation.
-Rob