An first step to improving the performance of a QV Document is to remove unused fields from the data model. A tool that can assist with this process is DocumentAnalyzer, freely available for download here.
I first blogged about DocAnalyzer in 2009. It’s since undergone a number of improvements and there is a whole new audience of QV Developers out there. I thought it was worth revisiting.
DocumentAnalyzer is a QVW that analyzes another QVW and identifies Fields that are unused by the UI. That is, Fields that are not used in expressions, dimensions or keys. These are fields that can probably be safely removed without affecting the user experience. I say “probably”, because DocAnalyzer is a guide; you must apply your own common sense and knowledge of the application before following it’s recommendations.
DocAnalyzer uses a macro that requires system access. Allow system access when prompted. The main sheet provides an input field for specifying the document (target document) to be analyzed:
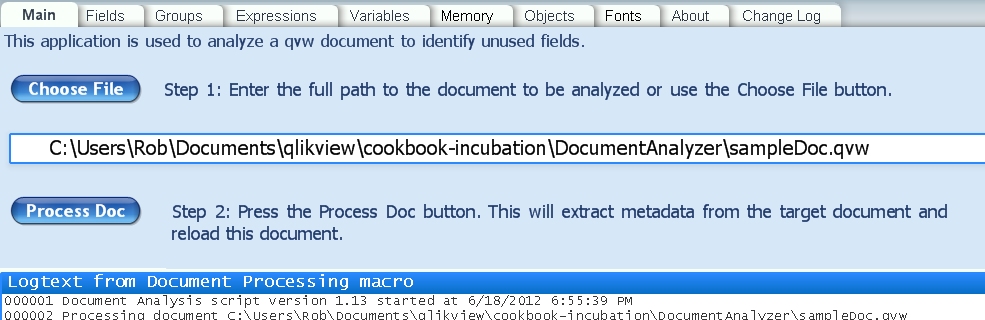
In the input field, enter the path to the target document. You may alternatively use the “Choose File” button to open a file chooser dialog. The usability of the chooser dialog is dependent on the windows version.
After entering a target name, press the “Process Doc” button. DocAnalyzer will open the target document and extract the info required for analysis. When the analysis is complete, you will see the popup

Press OK to continue and review the results.
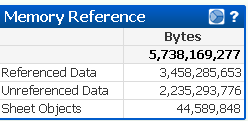
A good place to start is the “Memory” sheet. The Memory Reference chart will show how many bytes are represented by unused (Unreferenced Data) fields, and therefore how much memory could be saved by removing those fields. In this example 2.2GB of data is unused!
Next go to the “Fields” sheet. Select “N” in the FieldIsUsed listbox. Sort the Bytes in the “Field References” chart. This will identify the amount of memory occupied by each unused field.
It makes sense to consider removing the “OrderTime” field. It uses about 90MB. The other fields are small. You may want to remove them for neatness but the impact on performance will be insignificant.
A field may be required as part of the script processing or it may have been loaded by a “LOAD *”. A simple way to remove it from the model is to add a
DROP FIELD OrderTime;
at the end of the script.
In addition to identifying unused Fields, DocAnalyzer has picked up a couple of useful features for understanding target documents.
– The Groups sheet show the composition of Groups and their use.
– On the Object sheet, select to a single objectId. Clicking the “Goto Object” button will take you to that object in the target document.
– A customer requested the ability to analyze consistent font usage in his application. While not really the mission of DocAnalyzer, I had the framework there I so added the Font sheet.
If you have problems or questions on DocAnalyzer, please follow the reporting instructions on the About sheet. If you are reporting a possible bug, please include the contents of the Logtext on the Main sheet in your report.
-Rob